Appearance
Configuración de la herramienta PDF Query
La herramienta pdf_query permite consultar información de documentos PDF que han sido indexados mediante LlamaIndex. A continuación, se muestra la configuración y el código necesarios para que esta herramienta funcione correctamente.
1.Detalles de la herramienta
- Name:
pdf_query - Desc: Consulta información de documentos PDF indexados mediante LlamaIndex.
- Signature:
query:str -> str - Configuration:json
{ "url": "<url del pdf>", "name": "<nombre referencial>", "description": "<descripción del pd" }
- Agregar la herramienta al agente
- Ve a la sección de configuración de tu agente o a la herramienta personalizada donde deseas integrar la función.
- Copia y pega la estructura de configuración mostrada anteriormente en el lugar correspondiente.
- Asegúrate de reemplazar los valores por los tuyos (es decir, la URL del PDF que desees indexar, el nombre que quieras asignarle y la descripción apropiada).
- Código de la herramienta
A continuación, se presenta el código que permite descargar el PDF (si no existe) y crear o cargar el índice para realizar consultas:
python
import os
from urllib.request import urlretrieve
from llama_index.core import VectorStoreIndex, StorageContext, load_index_from_storage
from llama_index.core import SimpleDirectoryReader
# Obtenemos valores de configuración
url = config['url']
name = config['name']
storage_path = f'./storage/{name}'
filename = f'{name}.pdf'
# Verificar si el directorio de almacenamiento existe
if os.path.exists(storage_path):
# Cargar índice existente
storage_context = StorageContext.from_defaults(persist_dir=storage_path)
index = load_index_from_storage(storage_context)
else:
# Descargar PDF si no existe
if not os.path.exists(filename):
urlretrieve(url, f'./{filename}')
# Crear directorio de almacenamiento
os.makedirs(storage_path, exist_ok=True)
# Cargar documento
docs = SimpleDirectoryReader(input_files=[f'./{filename}']).load_data()
# Crear índice vectorial
index = VectorStoreIndex.from_documents(docs)
# Persistir índice
index.storage_context.persist(persist_dir=storage_path)
# Crear motor de consulta y ejecutar consulta
engine = index.as_query_engine(similarity_top_k=3)
response = engine.query(query)
return str(response)Ejemplo de como debería quedar la configuración:
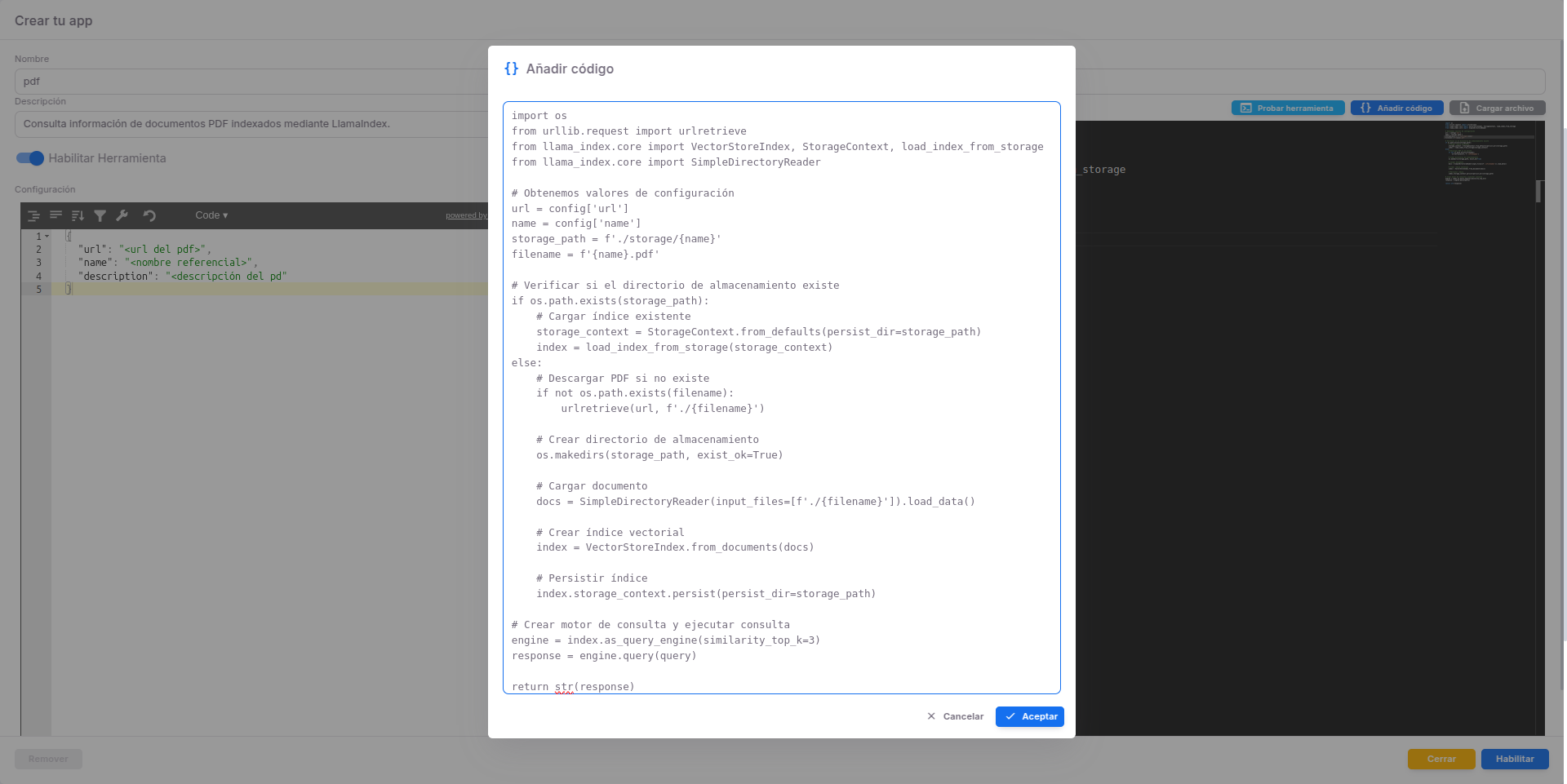
No cambies la estructura de configuración ni el flujo general del código, a menos que comprendas la lógica interna de la herramienta.
- Cómo funciona el código
- Descarga o utiliza el PDF: Verifica si el archivo ya está guardado localmente; si no, lo descarga.
- Crea o carga el índice:
- Si existe el directorio de almacenamiento (
storage_path), recupera el índice guardado. - De lo contrario, crea un índice vectorial nuevo a partir del PDF.
- Si existe el directorio de almacenamiento (
- Consulta el índice: Genera un motor de consulta (
as_query_engine) y ejecuta la búsqueda. - Devuelve la respuesta: La función
return str(response)envía la respuesta resultante de la consulta al agente.
- Prueba y validación
- Envía una consulta: Una vez configurada la herramienta, puedes preguntar algo sobre el contenido del PDF para verificar su funcionamiento.
- Observa la respuesta: El agente devolverá la información basada en el índice creado.
- Asegura la activación: Verifica que la herramienta aparezca como "Activa" en tu plataforma o agente.
Con esto, la herramienta pdf_query_custom quedará configurada y lista para procesar consultas sobre tu documento PDF.